
Your online devices may be broadcasting more about you than even your psychiatrist knows — and this private information is being used by people who want your business, your money, your vote, and much more.
Big data is what its name says: large and complex data sets created by the ever-escalating public use of the internet. We are all, in fact, co-creators of this juggernaut, because we leave a digital trace of our every online action as we go about our daily lives. The resulting data footprint can be read for insights into everything from our personal interactions to our political opinions and behavior. It is estimated that by next year every person will generate about 1.7 megabytes of data per second.
Our relation to big data is often seen in terms of our expectations of privacy. We all have the vague suspicion that, yes, our phone‘s microphone might be turned on by an app for no good reason or that the robot vacuum cleaner is beaming the layout of our home to some mysterious database.
Privacy in the world of mobile apps, social media, and constant connectivity seems nearly impossible. For the youngest generation of digital natives, the very idea of privacy may appear quaintly obsolete. When nothing can be kept private, why worry about it, especially if — in the words of some surveillance-happy government agents — you have nothing to hide?
But for those who are not quite ready to concede that unlimited electronic eavesdropping is the new norm, a deeper drive into the specifics may point the way to a different kind of accommodation with big data.
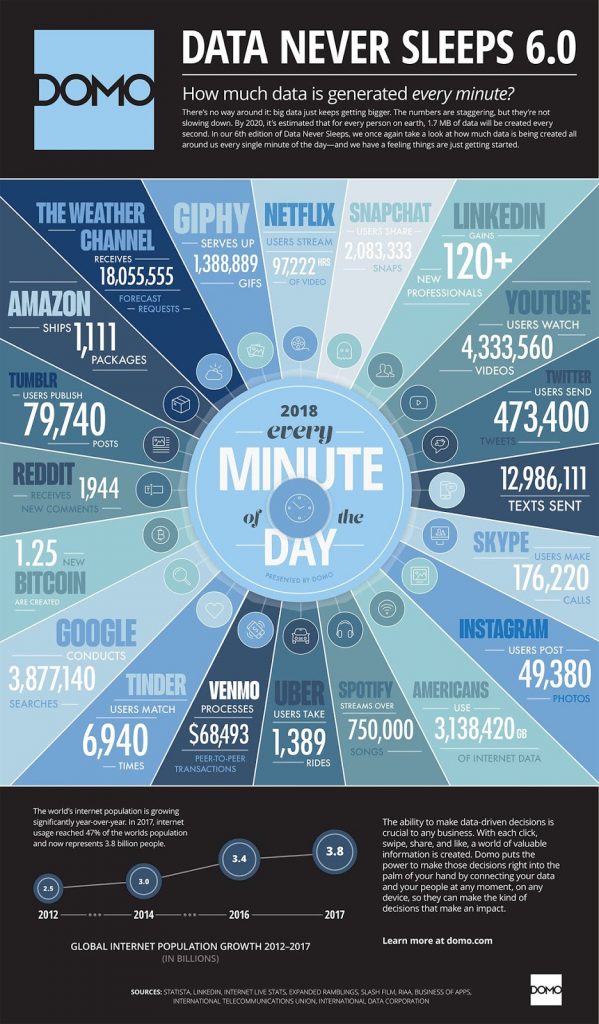
Big data’s size and complexity call for ever more sophisticated modes of data analysis and when artificial intelligence (AI) is brought into the picture data analysis becomes even faster and more effective. However — it creates access to previously inaccessible information, such as the connection between Facebook likes or Googling habits and intelligence, ethnicity, or income.
Such data associations make for an entirely new, online ad economy in the form of targeted marketing. Feeding off available big data, AI algorithms profile people based on their potential buying behaviors and market to them accordingly, via search engines, social media, and other media platforms. The content of these platforms is also mediated by big-data-fed algorithms — inferring what content keeps you interested, making you stay online longer… so you can be served more ads.
In the US, this information is freely collected, both by tech companies when users sign up for their service, and by data brokers. Data brokers accumulate information from a variety of sources — from credit card records to browsing history and geolocation — sometimes via buying and curating unstructured datasets, or by collecting it via GPS technology.
After creating complex profiles of the people they collect information on, they sell the curated data to companies for marketing purposes. Most of these companies are unknown to the general public. They only come to the forefront of public discussion when they accidentally leak data — such as the recent case with Equifax in the US.
https://www.youtube.com/watch?v=4IMq8yUMP7c
While US data regulation is far in the future, as of May 2018 the EU has adopted the General Data Protection Regulation (GDPR) after three years of negotiation. In short, the legislation gives the right for European citizens to consent to the use of their personal data, know what personal data the various companies hold on them, and demand for that data to be deleted.
This is referred to as the right to be forgotten. Legislation is enforced by the Data Protection Agencies (DPA) of the respective member states. Upon noncompliance, companies are faced with crippling financial penalties.
“The more serious infringements go against the very principles of the right to privacy and the right to be forgotten that are at the heart of the GDPR,” an EU website, set up to make GDPR more accessible, explains. “These types of infringements could result in a fine of up to €20 million, or 4% of the firm’s worldwide annual revenue from the preceding financial year, whichever amount is higher.”
GDPR has mostly meant the end of the European data broker economy. Meanwhile, the viability of last year’s GDPR legislation is currently being tested in Ireland, host to the European headquarters of many American tech-giants. This includes Google and Facebook, both under scrutiny for breaches in data consent. Since the implementation of the GDPR, there have been 59,000 breaches reported across Europe.
Targeted Sales Hunt the Disturbed Mental State
To some, targeted content might not seem like a terrible idea. Indeed, being served personally relevant content could be seen as rather attractive and practical. However, big data algorithms do not just pick up on socioeconomic data, they also provide complex inferences — exposing information that you might not want to share. For example, algorithms can recognize the onset of a bipolar manic episode or depression.
“Data from Internet and smartphone activities, and from sensors in smartphones and wearable technology, are routinely being used to monitor mental state and behavior for nonmedical purposes such as behavioral advertising,” a recent study notes.
Based on such data, algorithms can, for example, identify a pattern that reveals it is easier to sell subscriptions to gambling sites or flights to Las Vegas to people entering a manic phase of their mental disorder, as techno-sociologist Zeynep Tufekci explains in the following TED video.
Tailoring Media Based on Inferred Politics
The ability to make such complex inferences has serious political and social implications. In an article published in the New York Times last year, Tufekci conducted an experiment where she let YouTube‘s autoplay function run after watching rally videos of Donald Trump’s 2016 campaign.
“Soon I noticed something peculiar,” she said. “YouTube started to recommend and ‘autoplay’ videos for me that featured white supremacist rants, Holocaust denials and other disturbing content.”
Creating another YouTube account and running videos of Hillary Clinton’s campaign, she soon found the same pattern, confronted with increasingly radical left conspiracy theories:
“Before long, I was being directed to videos of a leftish conspiratorial cast,” Tufekci added. “As with the Trump videos, YouTube was recommending content that was more and more extreme than the mainstream political fare I had started with.”
While it might be easy to dismiss this as a political question, as Tufekci discusses, this is a fundamental structural issue. In the fight to make you stay on the site longer and serve you personalized ads, big-data-driven algorithms seemed to have picked up on the fact that people can be drawn incrementally to extreme or inflammatory content. Watch a video about vegetarianism, and you will soon find yourself listening to vegan activists, she concludes.
Profiling you on your interest and aiming to keep you engaged, sites can lead you down a rabbit hole of confirmation bias: leading you from progressive taxation to communism, or from free market capitalism to fascism.

When marketing political or nonpolitical content, algorithms can also mobilize people who have not explicitly searched related content, but who the algorithm suspects might be susceptible to it, based on psychologically tailored ads.
“We already have been seeing the results of negative segmentation we saw in the past before, like when cigarette companies were targeting low-income people,” says Juan Mundel, professor of advertising at DePaul University. Due to big data, Mundel continues, “Facebook also knows when you’re motivated to do something, when you’re feeling down, when you’re feeling all sorts of emotions.”
This allows hyper-specific marketing, exploiting not just your ideological beliefs and socioeconomic background, but your deepest psychological vulnerabilities. It is easy to see the advantage this tool provides to a marketing manager — but also to an anti-Semitic political leader or a predatory advertiser.
And there is something called “emotional contagion” through social networks. A 20-year study revealed that many people were led to vote in the 2010 US Congressional elections by messages showing that a close Facebook friend had already voted.
The problem here is not personalized marketing or abstract questions of privacy but, rather, that our reliance on these algorithms contributes to a world where there is no common basis of information — because we are literally being served different content. Further, the extent of our daily manipulation is entirely unknown to us; without realizing it, we are constantly exposing our vulnerabilities with each click of a button.
In this light, it is easy to see the recent GDPR regulation as a historic event, marking a fundamental shift in the way we see influence and politics. All this adds up to a strong case for data regulation in the US, as it plunges headlong into an uncharted era of post-truth politics.
Related front page panorama photo credit: Adapted by WhoWhatWhy from TheDigitalArtist / Pixabay.


